Forms Recognition and Processing SDK Technology
Forms Recognition and Processing SDK Technology

LEADTOOLS Forms Recognition and Processing technology provides unmatched document analysis and data extraction capabilities for .NET (C# & VB), C/C++, and web developers. LEADTOOLS incorporates a comprehensive collection of state-of-the-art features—scanning, image cleanup, OCR, OMR, ICR, barcode, and more—to automate the entire document image life cycle and yield unprecedented savings in time and resources. Moreover, LEADTOOLS has developed a fast, world-class forms recognition and processing algorithm capable of handling millions of pages per day.
Forms come in a variety of shapes, sizes, and uses, and LEADTOOLS has the tools to handle them all. In addition to basic forms recognition with static field locations, LEADTOOLS is able to detect and process unstructured and semi-structured documents such as invoices, driver’s licenses, and passports.
Overview of LEADTOOLS Forms Recognition and Processing SDK Technology
- Recognise and extract form fields regardless of image resolution, scale, and other form generation characteristics
- Machine-printed characters and numerals (OCR)
- Checkboxes and bubbles from surveys and tests (OMR)
- Handwritten characters and numerals (ICR)
- 1D (Linear) and 2D barcodes, including UPC, EAN, Code 128, QR Code, Data Matrix, PDF417, USPS, and 4-state
- Images of artifacts such as signatures, pictures, logos, and fingerprints
- Advanced form alignment algorithm compensates for non-linear deformations introduced by different scanners, printers, and resolutions
- World-class accuracy and speed
- Super-efficient forms classification algorithm can recognise forms from huge collections (e.g., 1000+) in less than two seconds
- Recognise and process unstructured and semi-structured forms
- Invoices
- Checks
- Passports
- Driver’s licenses
- Credit Cards
- Extract text from fields with common headers such as name, address, and total, even when the filled form does not align with the master form
- Recognise vertical and horizontal text from the same document
- Support for large OMR forms (e.g., tests, surveys, etc.) with or without timing marks, achieving highly accurate results due to superior alignment
- Unique colour and bitonal image recognition for scanned documents and pictures
- Classify and process single and multi-page forms, including individual and out-of-order pages
- Automatic detection and correction of page orientation and skew angle
- Enhance recognition accuracy with powerful document cleanup and preprocessing, including dropout of form table lines
- Use regular expressions to find and validate text
- Advanced, user-friendly tools for creating master form templates including auto-OMR mark detection and bulk field renaming
- Organise forms into categories and sub-categories
- Comprehensive confidence reporting for each form field type
- Character location, size, and baseline
- Character attributes (end of word, end of line, and end of paragraph)
- Font properties (monospace, proportional, serif, sans-serif, bold, italic, underline, and strikethrough)
- Confidence values
- Load and save form identification information as XML for simplified storage and editing
- Utilise LEADTOOLS Fast Twain to rapidly scan documents
- Multithreaded OCR to power high performance, server-based applications
- Native 32 and 64-bit forms recognition and processing binaries
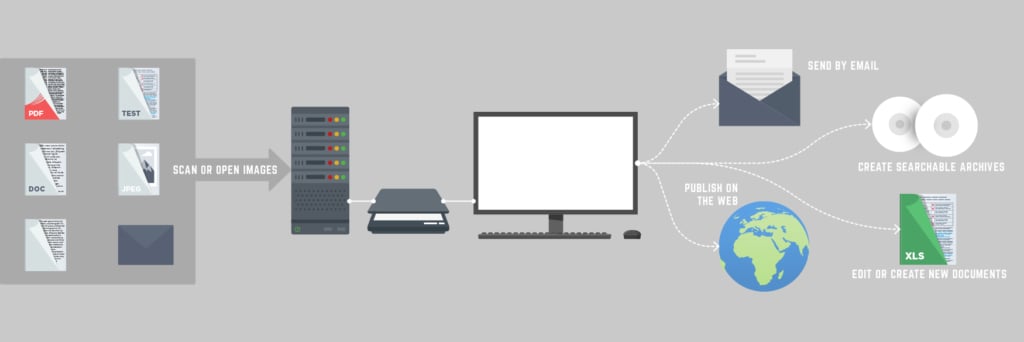
Forms Recognition and Processing Workflow